

Before we dive into the various concepts surrounding the topic of NLP, let us first understand what exactly it means.
What is NLP?
Natural Language Processing, commonly referred to as NLP in the world of computers, is a subcategory of Artificial Intelligence (AI) and Machine Learning (ML). Let's break it down. Natural language encompasses all the languages and dialects that we humans speak across the world. NLP focuses on the interaction between humans and computers using language that is "natural" to humans in terms of speaking or writing. It aims to bridge the gap between humans and computers by allowing computers to understand, process, analyze and generate natural language text.
Now that we know what NLP is, let us look at some basic concepts related to it.
1. Tokenization
Tokenization is basically breaking down text into smaller units called tokens. For example, ASCII codes which represent digits, lowercase letters, uppercase letters, etc. using a particular number (token). If we look at a word, say "SMILE", it can be written using ASCII codes as follows.
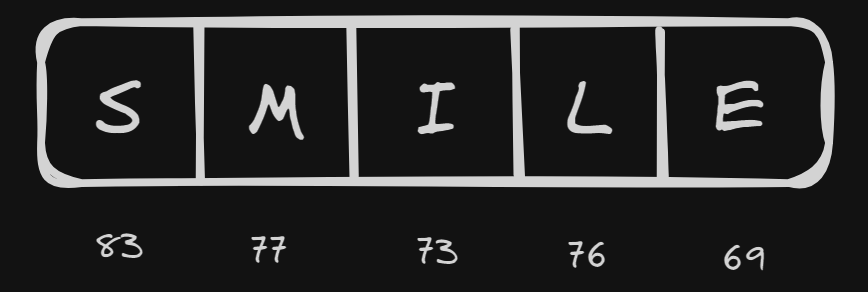
On the other hand, if we have a word like "LIMES" which is a rearrangement of the letters in "SMILE", the ASCII codes' arrangement changes accordingly.
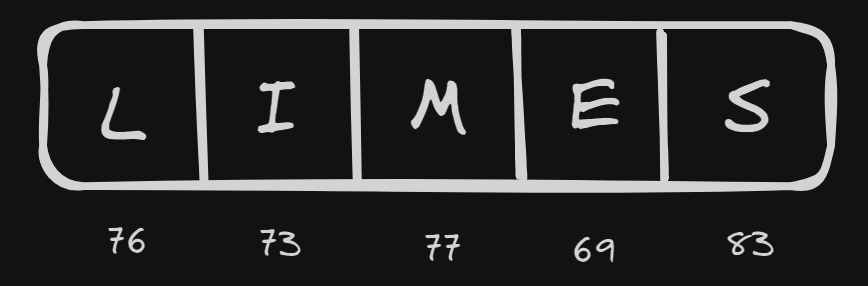
This makes it hard for us to understand the sentiment of the word and so, we tokenize words in a sentence instead of letters in a word. For example, we have the sentences: "I love apples" and "I love oranges". Their tokenization will be as follows:

Here, the words "I" and "love" have the same token in both the sentences as they are repeated. The words "apples" and "oranges" have different tokens as they are different words.
If we were to use TensorFlow in Python, it would further make things easier and would act smarter. If we look at the sentences below, we see that they are the same, just with the exception of an exclamation mark. TensorFlow is smart enough to understand that they are the same and will tokenize them accordingly.

2. Stop Words
Stop words refer to common words in NLP text that are removed or filtered out in order to make processing quicker and smoother. These words are usually the ones that do not carry specific semantic meaning in a particular context, for example, "the", "and", "to", "is", etc.
The main reason why we remove stop words from the text is so the computer can focus on the more meaningful words in the sentence. This helps improve performance and efficiency.
One thing to remember is that there isn't a particular list of stop words. They vary based on the context or the domain. For example, a word might actually convey an important meaning in the domain of sentiment analysis and should be retained.
Let us consider the stop word "the". In the sentence given below, it appears twice.

However, we see that even if we were to remove "the", the sentence would imply the same meaning, and so filtering it out helps improve processing efficiency.
3. Stemming
Stemming basically means reducing a word to its base or root form called the "stem" by chopping off any prefixes or suffixes present in the word. Even if the word after stemming isn't grammatically valid, we consider it, because it still implies the core meaning of the word. Following are some examples of stemming:
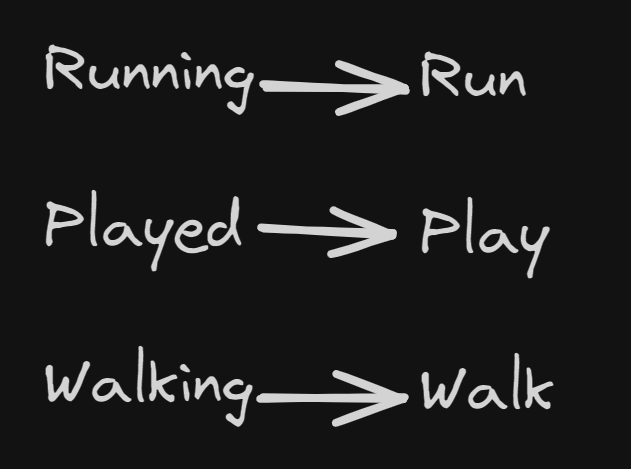
One of the most common stemming algorithms is the Porter Stemmer, developed by Martin Porter in 1980. It applies a series of rules to remove common suffixes from words. Other popular stemming algorithms include the Snowball Stemmer (a more improved version of the Porter Stemmer) and the Lancaster Stemmer.
4. POS Tagging
POS (parts-of-speech) Tagging refers to assigning each word in a sentence the corresponding tag of the part-of-speech which applies to it. Certain parts of speech include noun, pronoun, adjective, verb, adverb, preposition, determiner, etc. If we take a sentence, "The cat sat on the mat", each word can be assigned a particular category or part of speech as follows: "the"- determiner, "cat"- noun, "sat"- verb, "on"- preposition, "the"- determiner, and "mat"- noun.
POS Tagging helps in disambiguating the meaning of words and capturing the grammatical structure of sentences, which is essential for understanding and processing natural language text accurately.
5. Language Models
Language models are statistical models that are trained to predict the probability of a sequence of words or characters in a given language. These models learn the statistical structure of language from a large corpus of text data and can generate text, evaluate the likelihood of a given sequence of words, or perform various language-related tasks.
Following are some of the popular language models:
1. N-gram Models: One of the simplest forms of language models is the N-gram model, where N represents the number of words or characters in the sequence. For example, a bigram model considers pairs of consecutive words, while a trigram model considers sequences of three words. N-gram models estimate the probability of the next word in a sequence based on the preceding N-1 words. While N-gram models are simple and computationally efficient, they suffer from the "sparsity problem," especially for larger values of N.
2. Neural Language Models: Neural language models use neural networks, such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, Gated Recurrent Units (GRUs), or Transformers, to learn the sequential dependencies in language data. These models can capture long-range dependencies and contextual information better than traditional N-gram models. Neural language models are trained on large datasets using techniques like backpropagation and gradient descent to optimize model parameters.
3. Pretrained Language Models: Pretrained language models, such as OpenAI's GPT (Generative Pre-trained Transformer) and Google's BERT (Bidirectional Encoder Representations from Transformers), are trained on massive amounts of text data, often using large-scale unsupervised learning techniques. These models learn rich contextual representations of words or tokens and can be fine-tuned on specific downstream tasks, such as text classification, named entity recognition, or machine translation.
6. Sentiment Analysis
Sentiment analysis, also known as opinion mining, focuses on analyzing and understanding the sentiment or emotion expressed in the text. The goal of sentiment analysis is to determine the attitude, opinion, or emotional tone conveyed by a piece of text, whether it is positive, negative, or neutral.
The following are the key steps involved in sentiment analysis:
1. Text Preprocessing: The first step in sentiment analysis is to preprocess the text data. This may involve tasks such as tokenization, removing punctuation and special characters, converting text to lowercase, removing stop words, and stemming. Preprocessing helps to standardize the text and reduce noise before analysis.
2. Feature Extraction: After preprocessing, relevant features are extracted from the text data. These features may include individual words, phrases, n-grams (sequences of adjacent words), or syntactic patterns.
3. Sentiment Classification: Once features are extracted, machine learning models or techniques are applied to classify the sentiment of the text into predefined categories, such as positive, negative, or neutral. Classification can be done using various algorithms, including supervised learning algorithms and unsupervised learning algorithms.
4. Evaluation and Validation: After sentiment classification, the performance of the sentiment analysis model is evaluated and validated using specific metrics. Evaluation helps to assess the model's effectiveness.
If you want to check out a great example of sentiment analysis using NLP, you can access the sarcasm detection in news headlines dataset available on Kaggle: https://www.kaggle.com/datasets/rmisra/news-headlines-dataset-for-sarcasm-detection.
And with that, I'd like to conclude by saying that NLP has great scope in the future and a number of applications including sentiment analysis which I have discussed above. This blog covers only the basic concepts that go behind NLP and provides a foundation for absolute beginners. Thank you for reading and keep learning!